

Europe’s Leading
Cookieless Marketing Data Platform
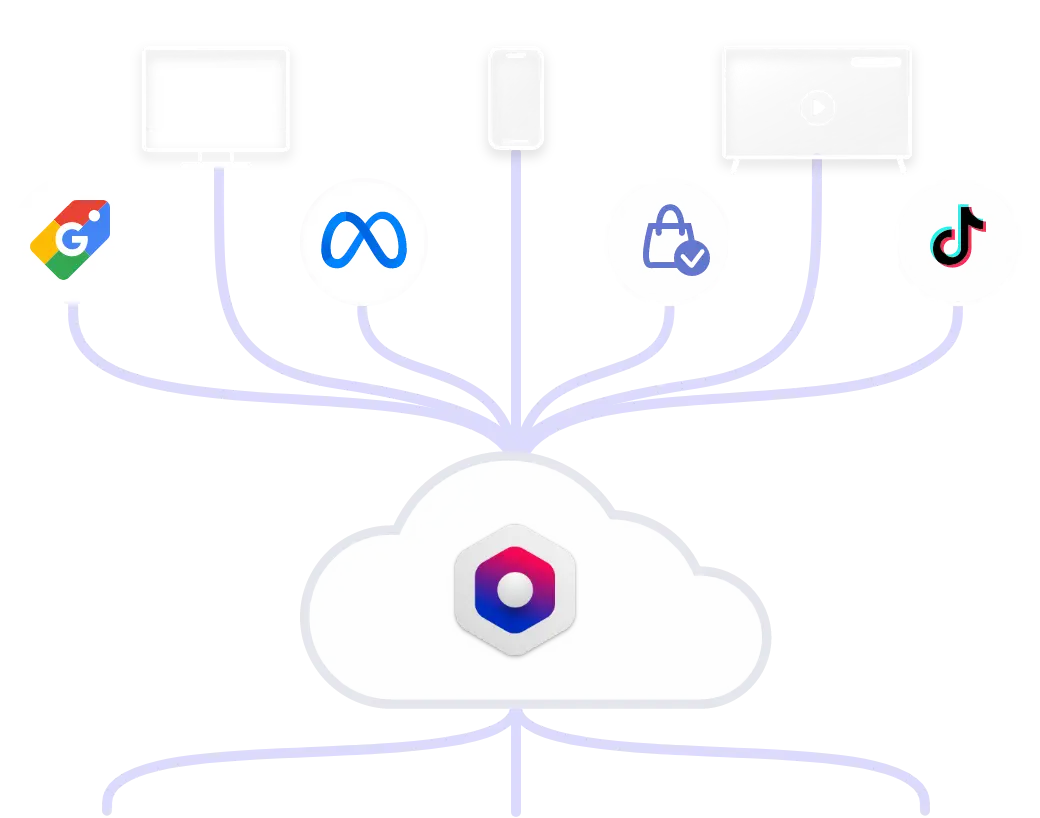
500+ leading companies are using Commanders Act Platform X to collect, analyse and activate marketing data with the goal of optimizing business growth.
Improved Data
Collection
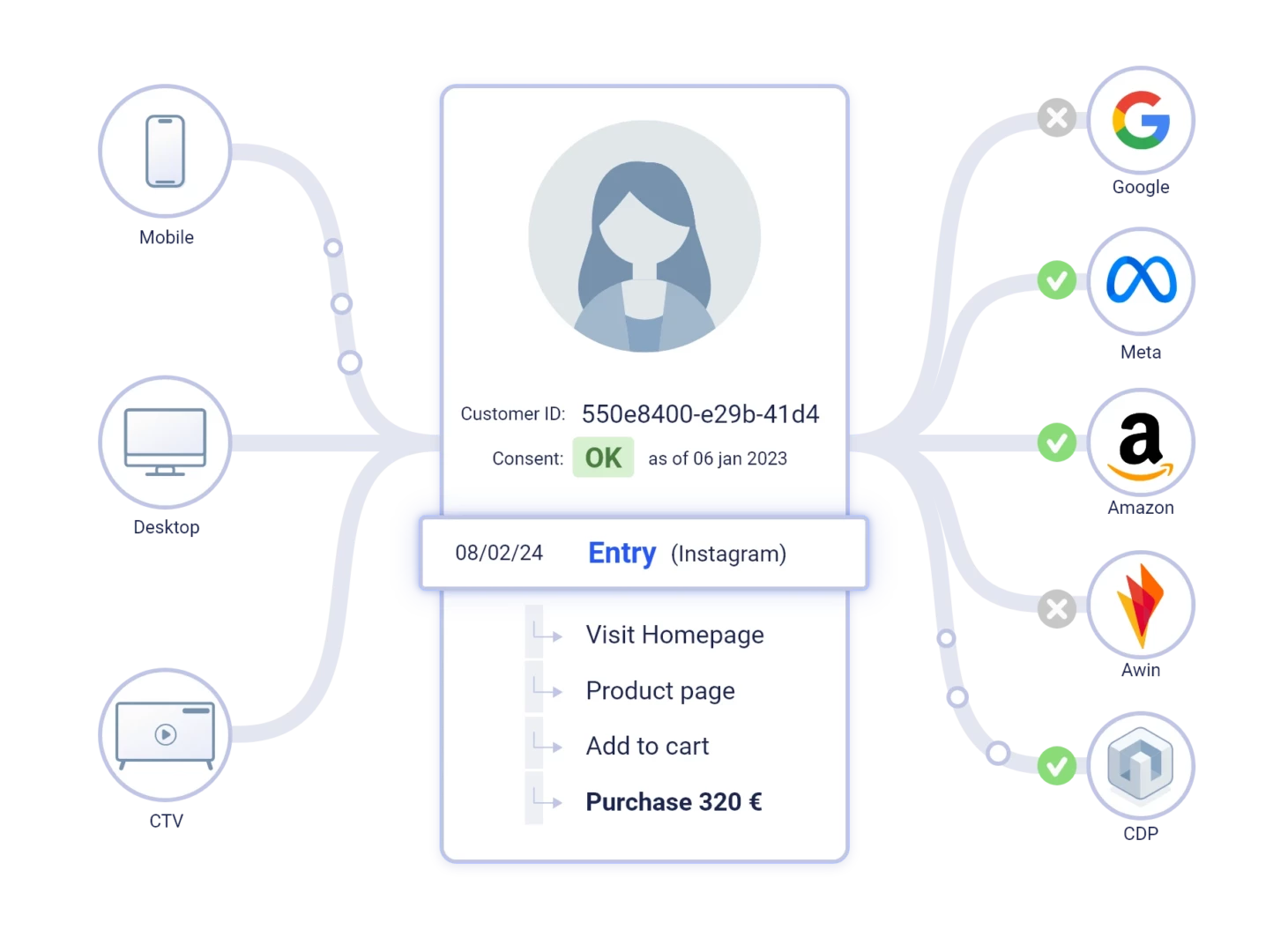
Cross Device
Matching
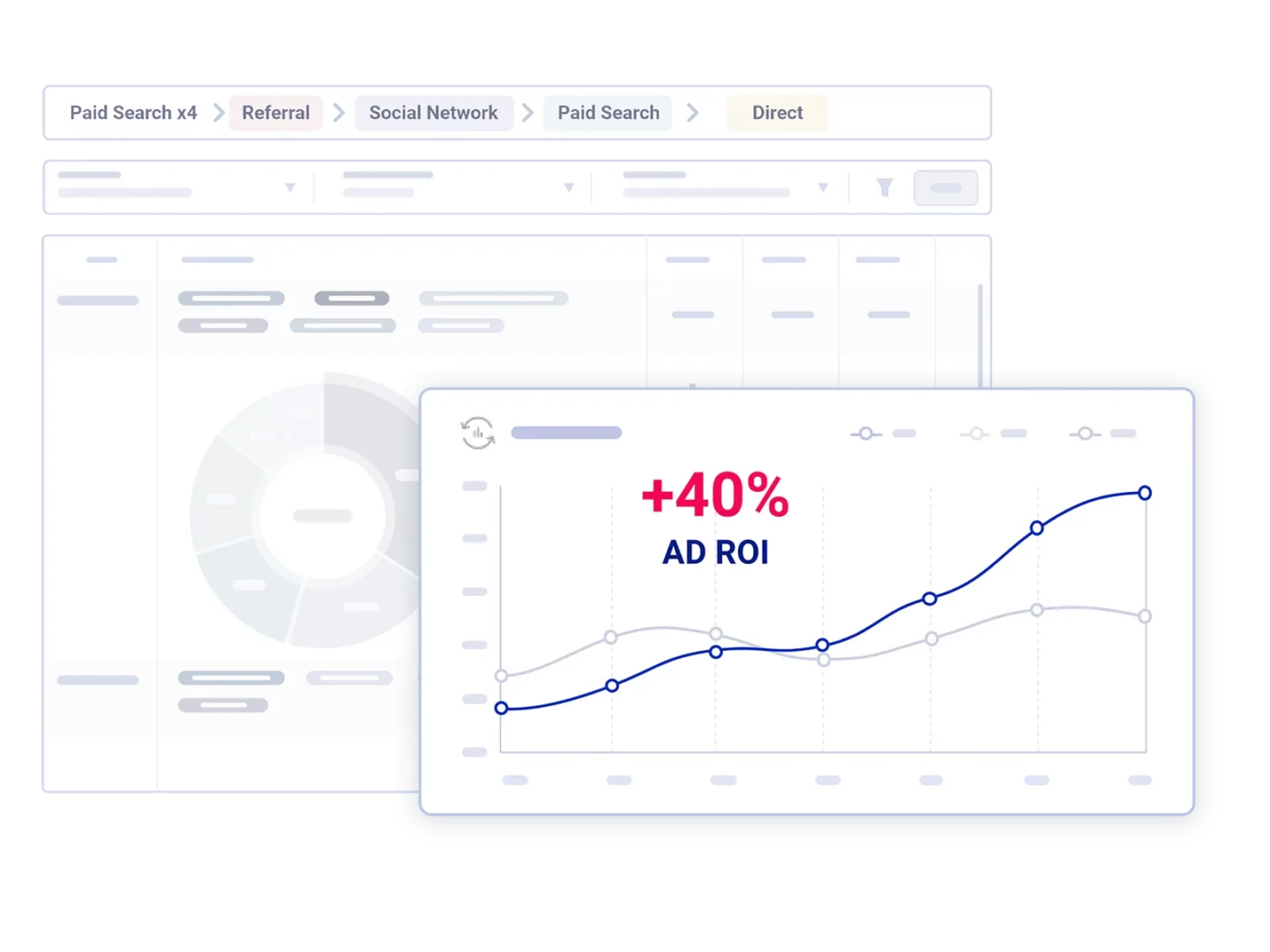
Ad Return
on Investment
JOIN THE 500+ COMPANIES USING OUR PLATFORM












A single enterprise-grade platform to drive business growth
Trusted customer data fuels better experiences
and increases ad budget efficiency
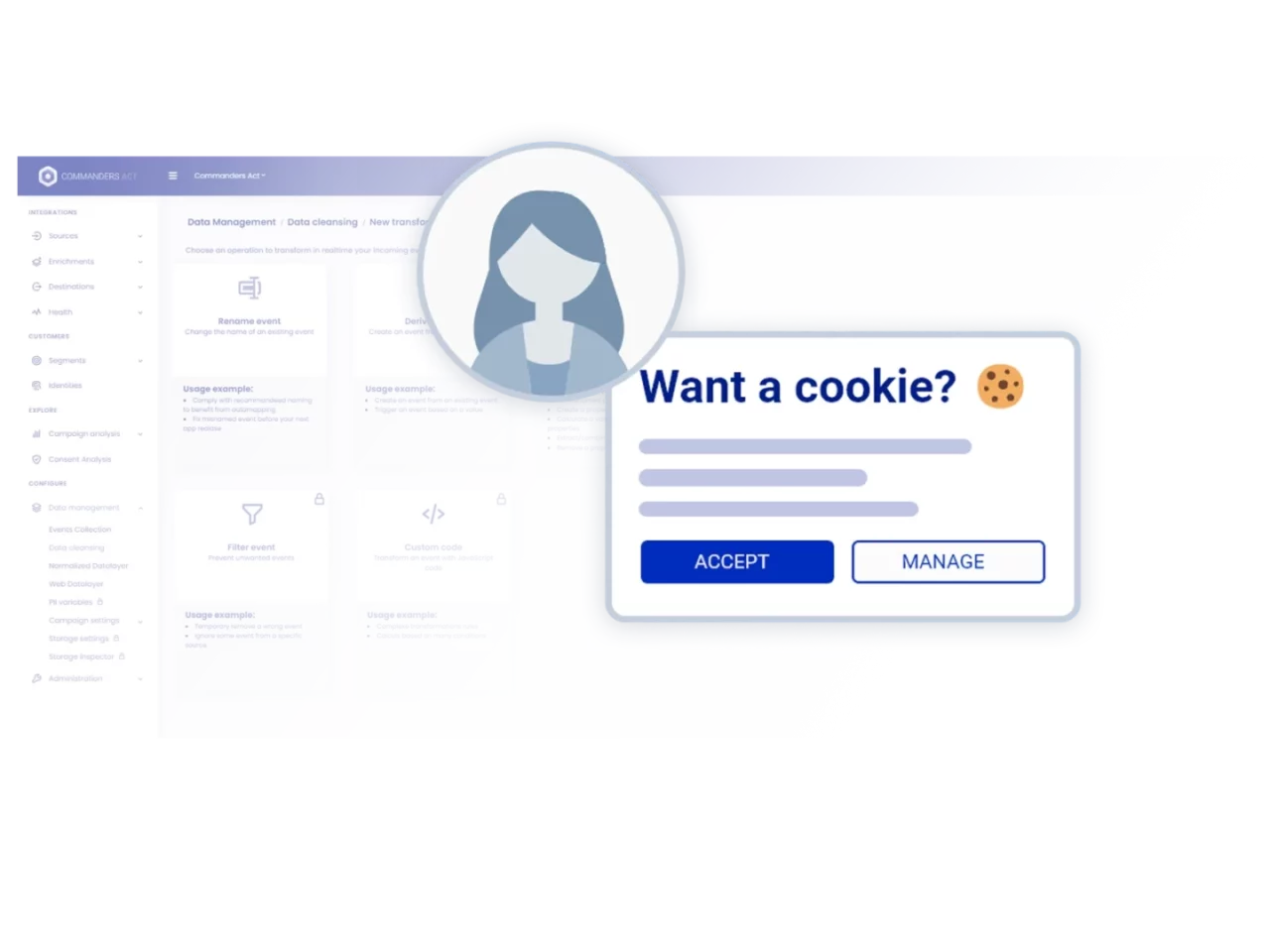
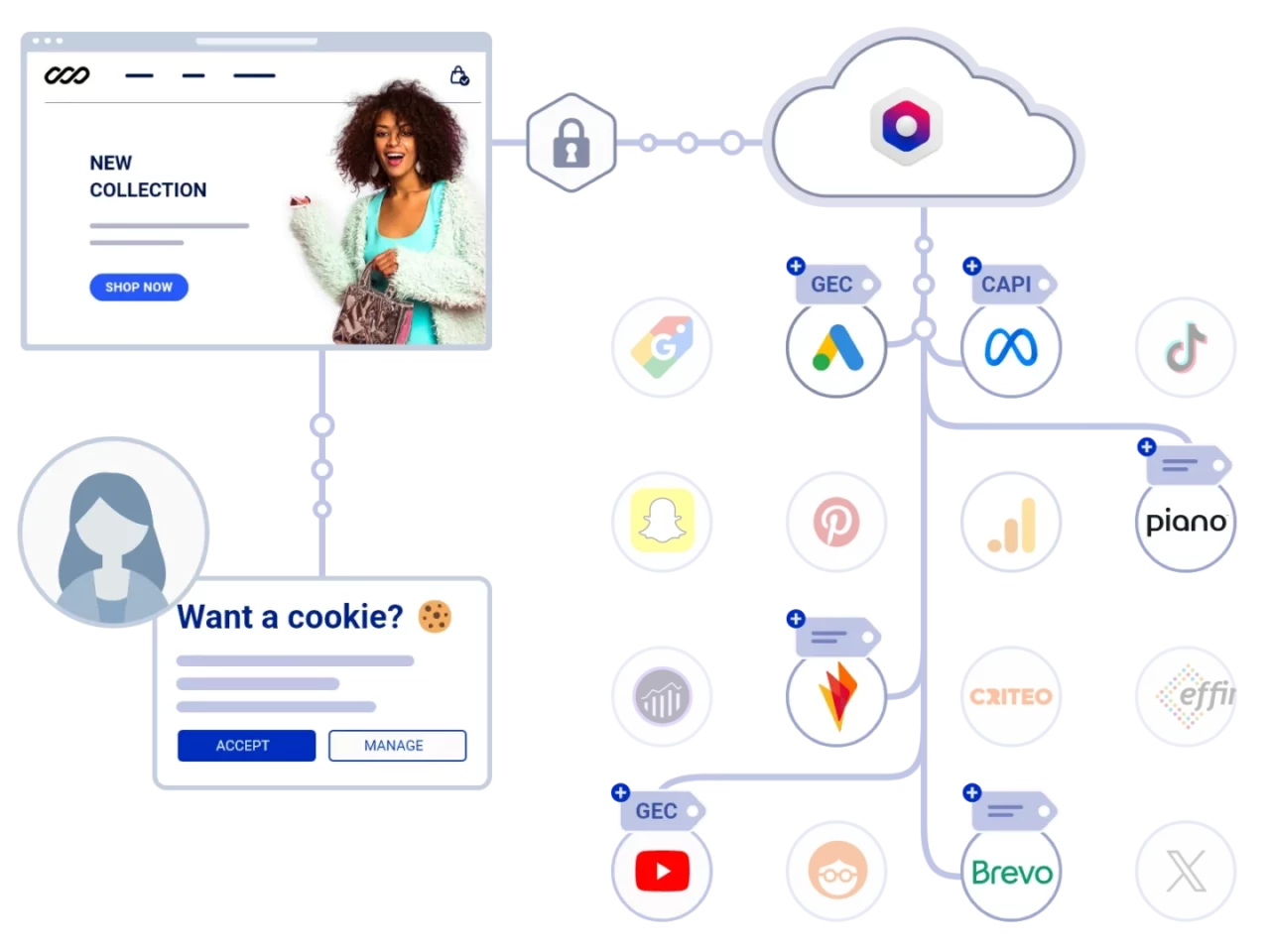
Trusted Data Collection & Delivery
Collect customer data in a privacy-compliant cookieless environment using our Client- & Server-side 1st-party tracking beacons.
Cookie KeEper
GTM-READY server side INTEGRATION
ACTIVATE GEC & CAPIS
COLLECT, OPTIMIZE, ACTIVATE
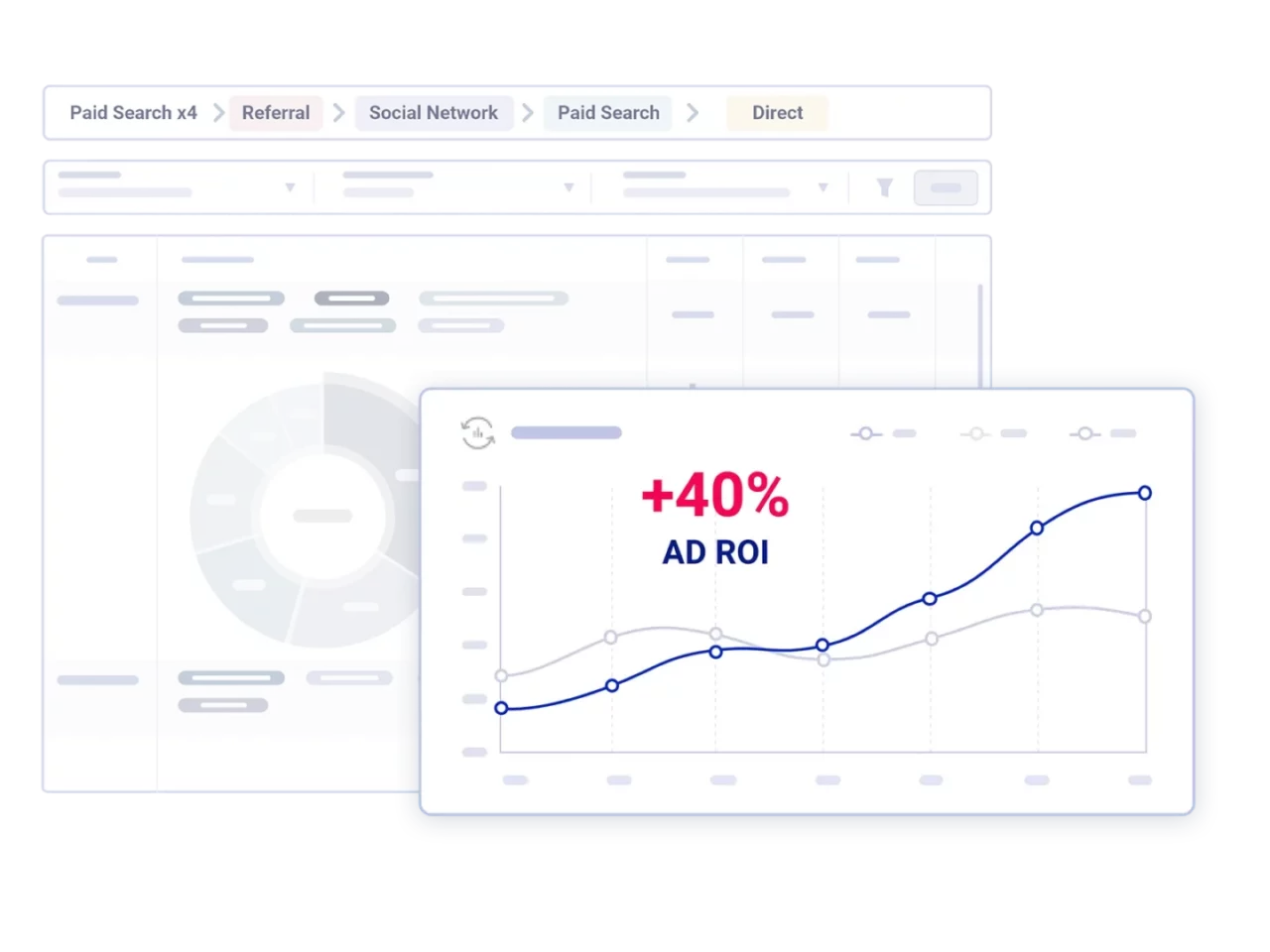
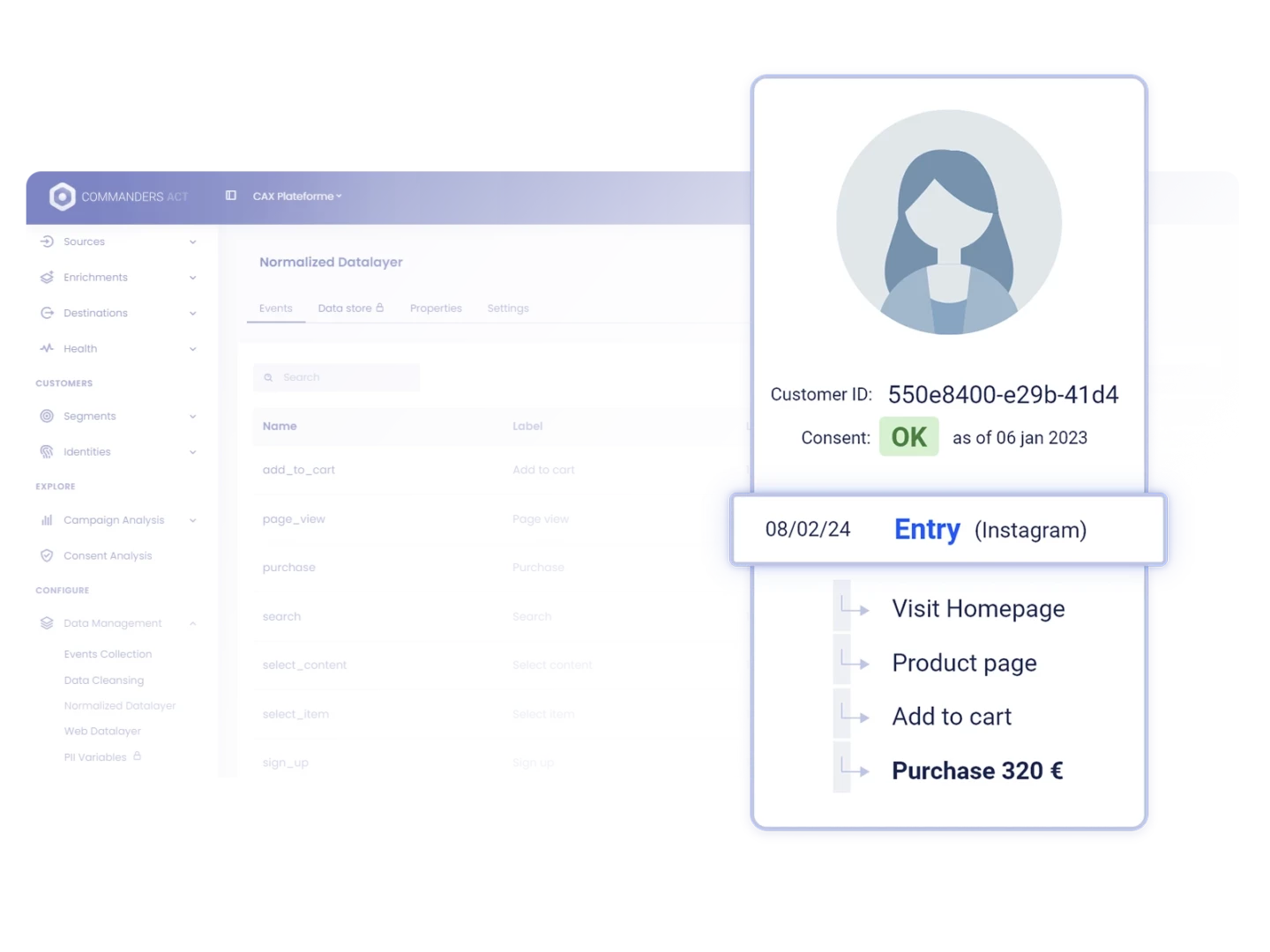
Leverage Trusted, Compliant Data to Increase Customer Activations & ROI

Trusted First-Party Data Collection

Ad Budget Optimization

Customer Profiling & Activation

Carole Vinatier Gresta
SEO & Tracking Manager
“
Over the years, the team members have proven to be highly available for supporting our changes, and strong ties have developed between both companies.
Customers Opt-in

Iskander Daagi
Digital Marketing Deputy Manager
“
The Commanders Act CDP has enabled us to refine our customer knowledge and optimise our digital levers.
average basket

Franck Lamendin
Head of Data Strategy Section
“
Thanks to the Server-Side approach, we have increased data collection across the various channels and reduced acquisition costs.
Data collected on Snapchat

Paolo Rohr
Digital Director
“
We chose Commanders Act for the flexibility of its offer and the availability of its teams.
of conversions

Sébastien Cvetojevic
Chief Revenue Officer
“
Today, we are able to ensure the continuity of tracking, enabling affiliates to be better paid.
of Data collected

1200+ Connectors
Let Your Data
Tell a Better Story
Trusted By
