Server-side : 10 mythes à déconstruire
14/04/2022 |

Dans le sillage du cookieless, le « server-side », autrement dit la collecte des données côté serveur, s’impose peu à peu dans la feuille des routes des équipes en charge du marketing digital. Une nouveauté qui suscite des questions, des doutes, voire des craintes. Et contribue à construire quelques mythes…
Mythe #1 : « Avec le server-side, les tags sont morts, le tag management aussi »
Il est vrai que le server-side est aussi désigné comme un procédé « tagless », sans tag. Facile d’en déduire donc que le tag management est mort. Sauf que la réalité technique est plus complexe. Toutes les solutions ne sont pas éligibles au server-side. Si le server-side est déjà possible pour l’analytics ou la gestion des consentements, il s’avère plus complexe à mettre en œuvre pour les ad servers ou les solutions de personnalisation. La transition va demander du temps et les deux modalités, traitements côté navigateur et côté serveur, vont cohabiter d’ici là. Nous n’en avons donc pas fini avec le tag management. Ce qui nous laisse le temps, aussi, de gérer l’inévitable évolution du métier – on y revient.
Mythe #2 : « Le server-side, c’est une affaire de développeurs »
Avec l’émergence du server-side se développe aussi le sentiment que le sujet du tracking change de camp, qu’il passe des mains des équipes marketing à celles des développeurs. Soyons clairs : c’est un (gros) raccourci. Oui, la mise en œuvre d’intégrations dites « tagless » est technique. Voilà pourquoi tout ne va pas se faire en un jour, mais plus probablement s’échelonner sur quelques années. Mais nous parlons ici de la mise en œuvre à travers les solutions du marché. Car une fois les solutions à jour – les gestionnaires de tags (qu’il faudra sans doute renommer) comme les solutions des partenaires –, le server-side reste à sa place : dans les coulisses. Et c’est bien aux responsables marketing qu’il revient encore et toujours de travailler sur les données collectées.
Mythe #3 : « Avec le server-side, une partie de mon job se volatilise »
Fini les tags, donc fini le tag management et… les jobs associés ? Les trafic managers et spécialistes du tagging doivent-ils s’inquiéter ? Pas vraiment. Tout est une question de définition du « tag management ». Si l’on considère que le tag management consiste avant tout à optimiser le placement des tags dans des containers exécutés dans un navigateur, alors, oui, ce tag management-là est appelé à disparaitre peu à peu.
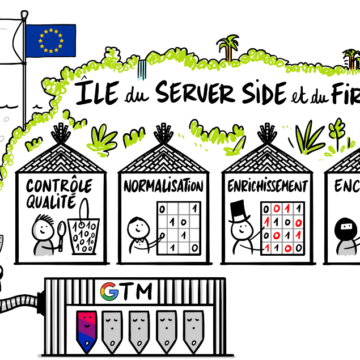
En revanche, si le « tag management » est aussi vu comme l’art de traiter la donnée avant de la transmettre à ces partenaires, alors le tag management est loin d’être mort. Au contraire, il entre même dans une nouvelle ère. Le server-side élargit sensiblement le champ des possibles, qu’il s’agisse de contrôler la qualité de la donnée, de l’enrichir ou encore de la distribuer avec précision aux partenaires. En résumé, le server-side représente un véritable appel d’air pour la créativité sur le front de la data.
Mythe #4 : « Le server-side, c’est une black box – on perd tout contrôle »
Ce sentiment est compréhensible. Le tag management côté navigateur donne le sentiment d’accéder à la collecte des données comme on lit dans un livre ouvert. Avec une mécanique gérée côté serveur, cette lisibilité semble révolue. En apparence seulement. Dans la pratique, tout reste bien sous contrôle et accessible : le gestionnaire de tags demeure le « hub » au sein duquel la collecte des données, leur traitement et leur envoi aux partenaires sont mis en œuvre. Au lieu de gérer des tags, la solution pilote des intégrations « tagless », de serveur à serveur, mais les rend toujours lisibles et manipulables.
Mythe #5 : « Le server-side, ça se gère en interne, avec des développements spécifiques »
C’est souvent ainsi que sont inaugurées les nouveautés techniques, surtout – et c’est encore le cas pour le server-side – quand tout le marché n’est pas encore au diapason de cette nouvelle donne. De fait, il peut être tentant de s’appuyer sur des développements maison pour maîtriser ces échanges de serveur à serveur. Une tentation qui perd de vue l’essentiel : l’objectif n’est pas seulement de mettre en œuvre le server-side mais de masquer sa complexité technique durablement afin que les équipes marketing puissent travailler de manière agile au quotidien. Un enjeu pour lequel un produit logiciel sera toujours plus éprouvé qu’un développement spécifique.
Mythe #6 : « Le server-side, ça va coûter cher… »
Le server-side appelant une refonte technique commune à toutes les parties prenantes, oui, des budgets dédiés sont requis. Mais ils doivent être considérés au regard des bénéfices obtenus. Le nombre de tags traités pour un site au sein du navigateur va se réduire sensiblement au profit de la web performance, donc de l’expérience utilisateur. Surtout, la bascule côte serveur permet un contrôle qualité et un enrichissement de la donnée hors de portée d’un traitement côté navigateur. La transition vers le server-side étant à peine amorcée, son potentiel est encore très sous-estimé. Probable qu’il conduise à transmettre moins de données aux partenaires mais… beaucoup plus pertinentes.
Mythe #7 : « Le server-side c’est un vrai SPOF »
Dans le lexique informatique, le SPOF, pour « Single Point of Failure » ou point de défaillance unique, laisse entendre que la disponibilité d’un système repose sur celle d’un seul de ses composants. Vu qu’avec le server-side toutes les interactions s’effectuent de serveur à serveur (et non de navigateur à serveur), la capacité du serveur-gestionnaire de ce dialogue à tenir la charge est questionnée. De fait, les infrastructures vont devoir être dimensionnées pour relever deux défis : d’une part collecter tous les hits, d’autre part traiter et partager la donnée. Bonne nouvelle : une solide expérience a été cumulée sur ce sujet. On sait par exemple, en cas de pic imprévu, « bufferiser » les traitements (les mettre de côté momentanément) pour les traiter par lots ensuite.
Mythe #8 : « Avec le server-side, je peux me passer du consentement »
C’est un raccourci à oublier au plus vite… Le « server side » est une modalité technique de collecte et de traitement des données. Il ne change rien aux précautions à prendre pour se conformer au RGPD (Règlement Général sur la Protection des Données) et aux directives de la CNIL sur la collecte du consentement. Que les informations soient transmises depuis un navigateur ou un serveur, le consentement de l’utilisateur doit être obtenu.
Mythe #9 : « Mettre en œuvre le consentement avec le server-side, c’est compliqué »
Si la gestion des consentements s’appuie sur un développement maison, qui n’a pas été conçu dans la perspective du server-side, oui, la transition peut s’avérer douloureuse. Ce n’est pas le cas pour des solutions comme TrustCommander, notre Content Management Platform, dont l’architecture a d’emblée été pensée pour s’inscrire dans un mode server-side. Ainsi, la propagation des consentements auprès des partenaires pilotés en server-side s’effectue de manière indolore.
Mythe #10 : « Avec le server-side, la confidentialité des données est forcément renforcée »
En matière de sécurité, rien ne va de soi. Ce n’est pas parce que les interactions sont gérées de serveur à serveur qu’elles sont naturellement plus sécurisées. Ce sera le cas si ces infrastructures sont auditées et sécurisées dans les règles de l’art, et si le trafic entre serveurs fait l’objet d’un chiffrement digne de ce nom. Précisons aussi que, selon les modalités techniques retenues, même avec le server-side, un datalayer peut subsister dans le navigateur et donc exposer des données. Si ces données sont sensibles, la mise en œuvre du server-side peut se faire sans requérir un datalayer. La sécurité du server-side relève donc d’un ensemble de mesures. Et de choix.